

If you follow the hardware for deep learning space, you may have heard of the term “systolic array”. A 2D systolic array forms the heart of the Matrix Multiplier Unit (MXU) on the Google TPU and the new deep learning FPGAs from Xilinx. If you are a computer architecture expert, then you know what systolic arrays are and perhaps even implemented a convolution or matrix multiplication on a systolic array in grad school. If you are like me – generally well versed in tech, but not a computer architecture expert, then you are probably a bit lost. In this post, I’ll explain what systolic arrays are and how a 1D correlation operation can be implemented using a systolic array. I’ll then show an animation of how the multiplication of two  matrices is implemented on a systolic array, which will help you understand the trade-offs made in systolic architectures. The operation of the MXU on a TPU is identical to the data flow shown in the animation. To provide a concrete example of the ideas discussed here, I’ll show relevant excerpts from the Google TPU Whitepaper.
matrices is implemented on a systolic array, which will help you understand the trade-offs made in systolic architectures. The operation of the MXU on a TPU is identical to the data flow shown in the animation. To provide a concrete example of the ideas discussed here, I’ll show relevant excerpts from the Google TPU Whitepaper.
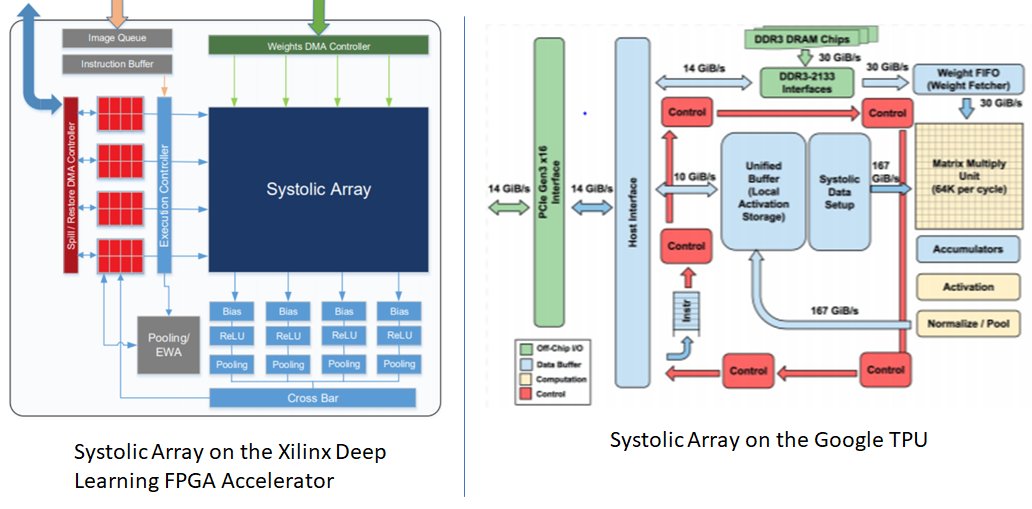
The term “systolic array” can sound like a new innovation in computer architecture. It isn’t. Like most ideas in deep learning, the concept of systolic array is decades old. See this review paper by H.T. Kung for a great description. The main idea is that general purpose processors such as CPUs are not optimal for special purpose, high performance applications. By identifying the key mathematical operation involved in the application, and decomposing the mathematical operation into a sequence of simple calculations such as multiply and accumulate operations, specialized hardware can be designed that performs a large number of these simple calculations in parallel. In this post, we’ll examine how this idea is applied to accelerate deep learning applications. We’ll first identify what this key mathematical operation is for deep learning systems and then see how it can be efficiently implemented using systolic arrays.
Deep Learning involves a number of calculations – convolutions, matrix-matrix (M-M), matrix-vector (M-V), application of non-linearities, calculation of loss functions, weight updates, max-pooling and so on. As shown by Bill Dally in his 2015 NIPS tutorial, M-M, M-V and convolutions are by far the most expensive operations and thus the prime target for optimization. Fortunately, these operations consist of a number of repeated multiply-accumulate operations. As shown here, convolutions can be converted into matrix-multiplication so it suffices to focus on matrix multiplication. We’ll come back to this point a bit later.

Applications can be compute bound or memory bound. Memory bound applications can’t benefit from HW acceleration as they are bound by how quickly data can be accessed, not by how fast data can be processed. Thus, an application must be compute bound to benefit from special purpose HW such as systolic architectures. A related issue is Arithmetic Intensity (AI). As mentioned in this post about Roofline charts, Arithmetic Intensity is an algorithm specific metric that measures the number of operations per unit data. It is equivalent to “data reuse” i.e., the number of operations that can be performed before new data needs to be fetched. Algorithms with high AI are preferable as they can achieve higher Ops (Operations per second) with a lower memory bandwidth (BW) and are therefore more likely to be compute bound. Fortunately, the AI of matrix multiplication (if implemented properly) is high – (2M-1)/3 for the product of two  matrices and proportional to the shorter matrix dimension for product of non-square matrices. This assumes that all matrix data is available in high speed memory which can be accessed at zero latency. However, if the load/stores involved in storing and retrieving the intermediate results of the sub-computations in a matrix multiplication are not handled properly, then those can turn a compute bound calculation into a memory bound one. Memory access also consumes energy and repeated reads/writes from local storage can consume a lot of power, as noted in the Google TPU paper.
matrices and proportional to the shorter matrix dimension for product of non-square matrices. This assumes that all matrix data is available in high speed memory which can be accessed at zero latency. However, if the load/stores involved in storing and retrieving the intermediate results of the sub-computations in a matrix multiplication are not handled properly, then those can turn a compute bound calculation into a memory bound one. Memory access also consumes energy and repeated reads/writes from local storage can consume a lot of power, as noted in the Google TPU paper.
![]()
Table of Contents
Systolic Architectures
A systolic system consists of a set of interconnected cells also called “processing elements” (PEs), each capable of performing some simple operation. Information can flow directly between cells in a pipelined fashion. This addresses the problem of storing/loading intermediate results that we mentioned earlier. Communications with the outside world occurs only at the boundary cells.
Systolic systems are similar to pipelined systems, but differ in a few ways. Systolic arrays can be 2D and data flow can be at multiple speeds in different directions. Both input and results can flow in systolic arrays, whereas only results flow in pipelined systems. The rhythmic data flow in systolic arrays keeps the control logic simple but also means that individual PEs cannot stall – if there is insufficient bandwidth, the entire array needs to stall.
To make these ideas more concrete, let’s consider how correlation, a close counterpart of convolution can be implemented using a systolic array of three “processing elements” (PEs). The correlation operation can be expressed as:



So, the output can be calculated by the dot product of the weight vector with time-shifted input vector. Let’s calculate the arithmetic intensity of this operation.
The number of operations: 3 multiplies and 2 adds
I/O: one input element is read and one output element is written back.
Thus, the arithmetic intensity is 5/2. For a  dimensional correlation, the arithmetic intensity is (2k-1)/2. This high arithmetic intensity is because of the high data reuse – each element of the output vector reuses two data points that have already been read. Thus, the correlation operation is a good candidate for a systolic array. This principle is true in general – high arithmetic intensity operations are good candidates for systolic architectures. Low AI operations are memory bound, and thus performing the calculations faster by adding parallelization or increasing the clock rate won’t help. The Google TPU paper makes this point in section 7 – “Evaluation of Alternative TPU Designs”
dimensional correlation, the arithmetic intensity is (2k-1)/2. This high arithmetic intensity is because of the high data reuse – each element of the output vector reuses two data points that have already been read. Thus, the correlation operation is a good candidate for a systolic array. This principle is true in general – high arithmetic intensity operations are good candidates for systolic architectures. Low AI operations are memory bound, and thus performing the calculations faster by adding parallelization or increasing the clock rate won’t help. The Google TPU paper makes this point in section 7 – “Evaluation of Alternative TPU Designs”

We can decompose the correlation operation into the individual multiply and add calculations and perform each calculation on a separate PE.
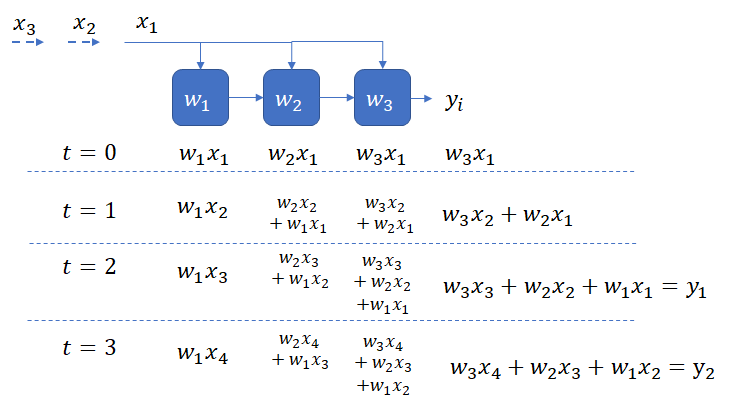
Each element of the PE array (other than the leftmost) stores a weight value, multiplies it with its input and adds the result to the partial sum calculated by the previous element. After the second time step, one element of the output vector is computed every clock cycle, and one input element is read. We are obtaining maximum possible throughput at the minimum required bandwidth and taking advantage of all data reuse available. This design is an example of a “weight stationary” design, as the weights stay stationary and the inputs are streamed in.
In this design, each  is being broadcast to all PEs. Another alternative is to cycle the sequentially through the PEs and and sum the partial sums using an adder.
is being broadcast to all PEs. Another alternative is to cycle the sequentially through the PEs and and sum the partial sums using an adder.
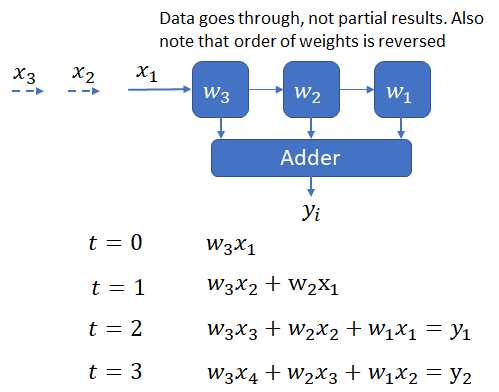
Each PE simply implements the multiplication operation. The add operation has been moved to the global accumulator.
A downside of both these designs is that either each element of the input must be broadcast to all PEs (in the first design) or the partial outputs must be collected and sent to the accumulator. Doing so requires the use of a bus, which must scale as the size of the correlation window increases.
An ingenious alternative is an “output stationary” architecture, where the results stay and the inputs and weights move in opposite directions. Each PE stores and accumulates the partial results. The  and
and  move systolically in opposite directions, such that when an
move systolically in opposite directions, such that when an  meets a
meets a  , they are multiplied and resulting product is added to the partial result at that PE. To ensure that each is able to meeting every
, they are multiplied and resulting product is added to the partial result at that PE. To ensure that each is able to meeting every  , a time step is inserted between consecutive elements in the input and weight streams. The execution of this scheme is shown below.
, a time step is inserted between consecutive elements in the input and weight streams. The execution of this scheme is shown below.
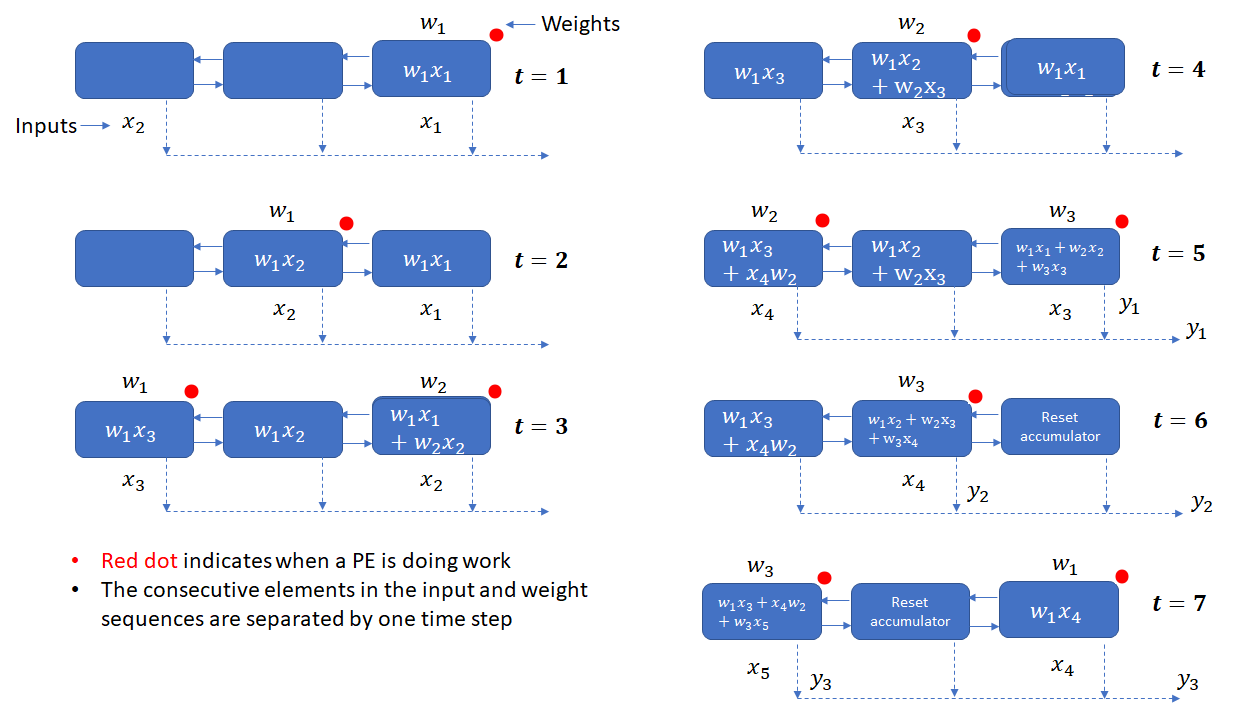
This design doesn’t require a bus or any other global network for collecting output from the PEs. A systolic output path, indicated by the broken arrows is sufficient.
While this design solves the problem of the global bus, it suffers from the drawback that each PE is performing useful work only one half of the time (as indicated by the red dots). Extra logic is also necessary to reset the accumulator in a PE once it completes calculation of a  . The paper by Kung offers a few other variations that make different design choices such as moving the weights and inputs at different speeds and adding extra storage in each PE. A summary of these choices is shown below.
. The paper by Kung offers a few other variations that make different design choices such as moving the weights and inputs at different speeds and adding extra storage in each PE. A summary of these choices is shown below.
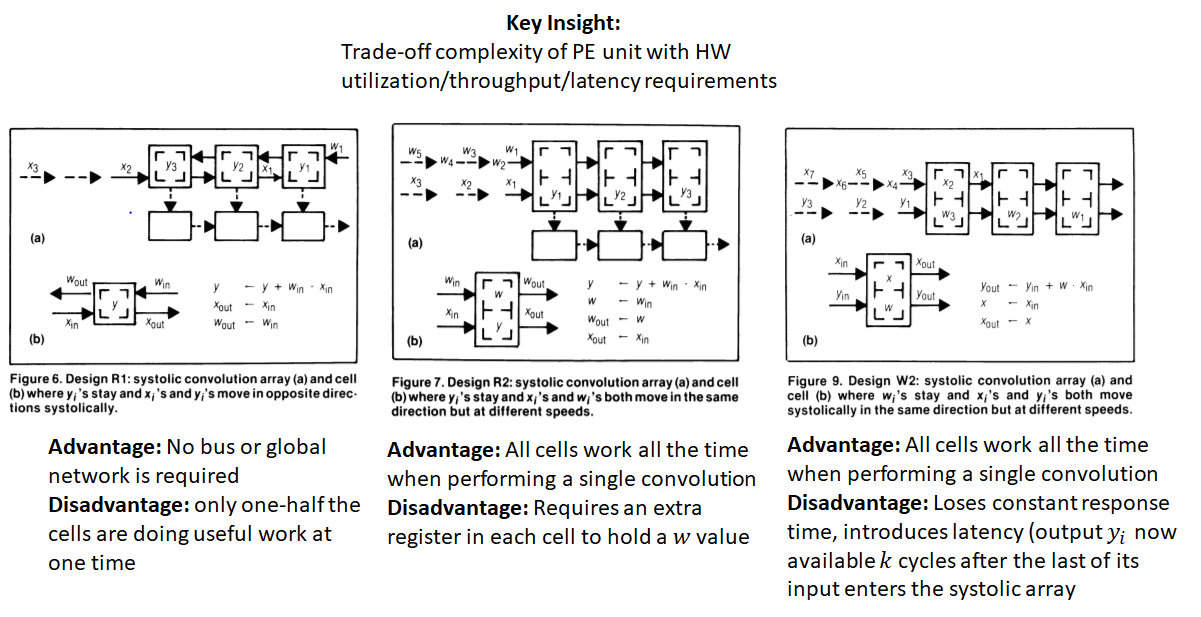
The key point to understand is that various trade-offs between HW utilization (how often is a PE doing useful work), throughput and latency can be obtained by adjusting the complexity of a PE and the surrounding HW (buses, timing hardware etc.)
Matrix Multiplication on a Weight Stationary 2D Systolic Array (MXU on a Google TPU)
The heart of the TPU is the systolic array consisting of a  (N=256) grid of Multiply-Accumulate (MAC) units. The TPU uses a weight-stationary architecture where the weights are pre-loaded into the MAC array and the activations are marched in from the activation storage buffer. The activations move horizontally from left to right and the partial sums move vertically from top to bottom. The results of the matrix product are fed to the activation unit which provides hardware support for common activation functions.
(N=256) grid of Multiply-Accumulate (MAC) units. The TPU uses a weight-stationary architecture where the weights are pre-loaded into the MAC array and the activations are marched in from the activation storage buffer. The activations move horizontally from left to right and the partial sums move vertically from top to bottom. The results of the matrix product are fed to the activation unit which provides hardware support for common activation functions.
The animation below shows the flow of activations and partial sums for two  matrices. The weight matrix
matrices. The weight matrix  is preloaded into the MAC units and the input matrices
is preloaded into the MAC units and the input matrices  are marched in from the left. The rows of each input matrix are offset in time. The product of the weight and input matrices is represented by
are marched in from the left. The rows of each input matrix are offset in time. The product of the weight and input matrices is represented by  where
where  etc.
etc.
Incidentally, making this animation and getting it to work in a WordPress post was quite interesting in itself, specially since I’m not a web expert. To make the individual frames of the animation, I drew the shapes and text in PowerPoint and saved the slides as bitmaps. I then used the EaselJS 2D animation library to play the frames as an animation. It is possible to execute custom Javascript code from a WordPress post, thus I could connect the click events generated when the user clicks on the Play/Stop buttons to the corresponding onPlay, onStop handlers in the Javascript code.
Coming back to our discussion, from this animation, it should be clear that it takes 2N-1 cycles to read all elements of the product of two matrices.
Note that since the weights are read much less frequently than the activations, the bandwidth into and out-of the activation storage buffer is much higher than the bandwidth of the weight buffer.
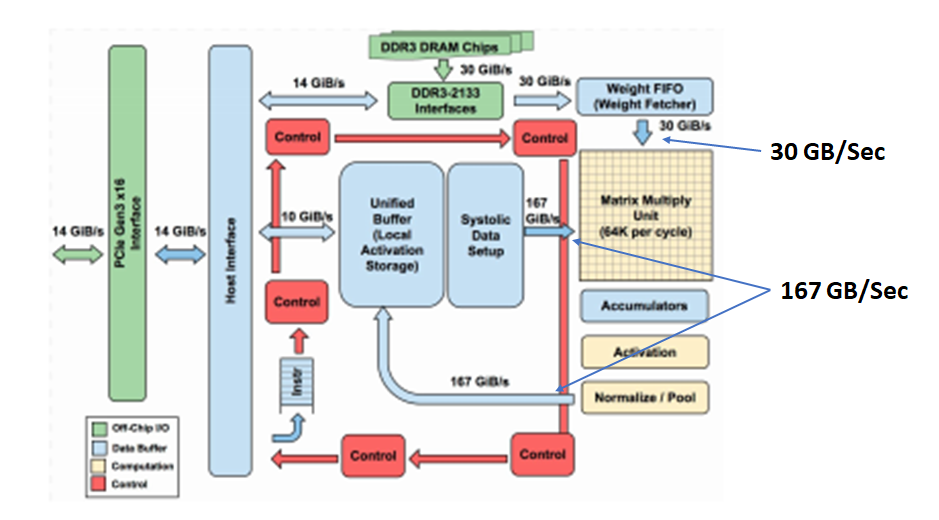
If the size of matrix-matrix multiplication is larger than the systolic array, the operation is performed in several blocks. The result of each block is stored in accumulators and is added to the result of the next block.
Advantages and Disadvantages of a TPU
Advantages
The key advantage of the TPU and systolic architectures in general is their simplicity. The TPU is a domain specific processor designed to do one thing well – matrix multiplication. It doesn’t implement general purpose features such as caches, branch prediction, out-of-order execution, multiprocessing, context switching etc., which keeps the design simple and power consumption low. This simple design means that control logic takes a very small portion (2%) of the overall chip space. The matrix multiply unit and different memory types consume the bulk of the space. This helps reduce chip manufacturing costs and overall energy consumption.
A key advantage of the TPU over a GPU is good hardware utilization for latency sensitive inference applications. A GPU needs batching to take advantage of all available hardware resources. Batching however introduces latency, which is not desirable for inference applications that may have a strict latency upper bound.
Disadvantages
Latency Depends on Matrix Dimensions
We saw earlier that it takes 2N-1 clock cycles to complete a product of two  matrices. For a batch of size B, the latency is N(B+1) -1 (see below). This implies that the latency of the matrix product depends upon the matrix dimension. This is not desirable for constant latency applications although it isn’t much of an issue for neural network inference as the size of the matrix dimensions are known in advance and the batch size can simply be adjusted to meet the latency bound.
matrices. For a batch of size B, the latency is N(B+1) -1 (see below). This implies that the latency of the matrix product depends upon the matrix dimension. This is not desirable for constant latency applications although it isn’t much of an issue for neural network inference as the size of the matrix dimensions are known in advance and the batch size can simply be adjusted to meet the latency bound.

Poor MXU Utilization and Wasted Memory BW for Non-Standard Matrix Dimensions
A bigger issue arises when the matrix dimensions are not a multiple of the MXU tile size. When the weight matrix is larger than the MXU, it will need to be tiled and for the last row and column of the tile, all of available MAC units will not be used. A simple example of systolic matrix multiplication with a partially occupied tile is shown below.

A partially occupied MXU tile also wastes memory bandwidth
The TPU paper says this:
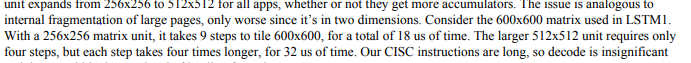
This implies that it takes the same time to load a fully occupied tile as a partially occupied one. Thus a partially occupied tile will waste memory bandwidth.
Implementing Convolutions as Matrix-Multiplications may not be Optimal
TPUs don’t have direct support for convolutions. Convolutions are implemented by converting them into matrix-multiplications. This may not be optimal (particularly for large convolution kernel sizes) as convolutions have specific data flow patterns that can be leveraged to achieve better efficiency. A great example is the Eyeriss accelerator that is specially designed for the convolution operation.
No Direct Support for Sparsity
It turns out that many of the connections in a deep neural network can be pruned without significantly impacting the inference accuracy. In this approach, less important weights are progressively removed and the network retrained for a few iterations until the desired performance characteristic – for example classification accuracy or total network size is achieved. More than 90% of the weights can be pruned without a significant impact on performance. Weight pruning can dramatically reduce the size of the network, number of operations and energy consumption. Sparsity is not currently supported on the TPU. This is as much of an opportunity as a drawback, because with hardware support for sparsity, significantly better performance should be achievable. Support for sparsity will add complexity to the TPU design though as the sparse weights will no longer be located contiguously in memory. For a great example of a specialized accelerator that performs customized sparse matrix vector multiplication and handles weight sharing with no loss of efficiency, see the “Efficient Inference Engine” paper. Also, the DL FPGA from Xilinx appears to support sparse matrix-vector computations.
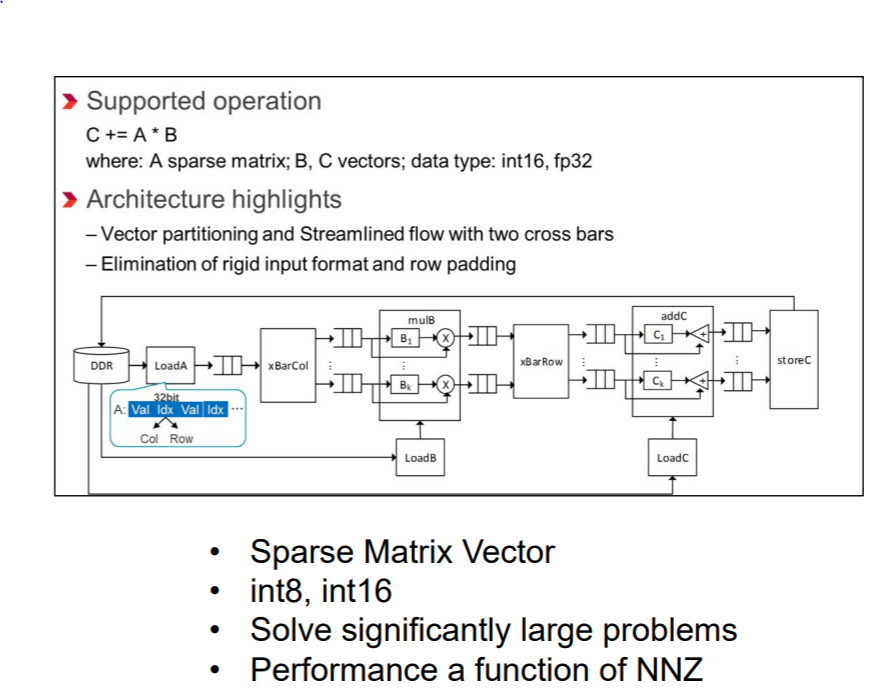
Pipelining of Weight Reads
It takes time to read the weights from the host memory to the AI accelerator on-chip memory and to transfer the weights to the matrix-multiply unit. Therefore, it makes sense to use pipelining to hide the corresponding latencies. The basic idea is to load the weights for the next network layer while processing the computations for the current layer. The TPU implements a 4 tile weight FIFO to transfer the weights from the off-chip DRAM to the on-chip unified buffer. The matrix unit is double-buffered so it can hold the weights for the next layer while processing the current layer. Without double buffering, it will cost 256 cycles to transfer the weights for the next layer from the unified buffer to the MXU. This is similar to “page flipping” in computer graphics. The Xilinx deep learning accelerators also implement pipelined systolic arrays.
Conclusion
The point of this article was to help you understand the main thrust of the innovations in deep learning hardware architecture which is to design custom hardware to speed up matrix computations, particularly matrix multiplication. Systolic architectures are a well-understood technique to implement high throughput matrix multiplication by using an array of interconnected multiply-accumulate units. Understanding how matrix multiplication actually works in a 2D systolic array helps to develop intuition about the pros and cons of systolic architectures. Since systolic architectures are being used in deep learning inference accelerators from many important market participants, this intuition should be helpful in making design choices about inference HW for your specific application.
Excellent read.
Thanks bob!
Very nicely written. Thank you for sharing!
I am wondering if you did any analysis on what other type of hardware compute units are proposed so far or being used other than the “Systolic array” for AI accelerators.
Thank you for your time.
Glad you liked the post. As examples of other compute units – search for Eyeriss, an accelerator for convolutional NNs and EIE (Efficient Inference Engine) for an accelerator for sparse matrix calculations. The references in those papers should provide many other examples.
Thank you very much for sharing the knowledge and this great post.
Thank you very much. I am working on accelerators currently and I find your post is very helpful for me to understand systolic arrays
Hello, really nice blog! By the way, where do you know that TPUs have no direct support for convolutions? Is there a particular source?
Hello, really nice analysis! Is there a source where it says that the TPU cannot support direct convolution? Or you just assumed it from the architecture?
This article is amazing! Finally, I understood what a systolic array is.
Thank you so much.
This is an amazing article! I finally understood what a systolic array is.
Thank you so much.
Relevant and good write up. Reading this even in 2025
Thank you for this. Saves me tremendous time trying to scatter/gather all the relevant literature on the different subtle micro-arch forms that have big consequences in the larger chip. Big fan.